Jsoup是不是叫爬虫框架我不清楚,只是比较应景,别深究。Jsoup功能非常强大,它可以使用 DOM 或 CSS 选择器来查找、取出数据。有人会说,我使用字符串操作函数构造取文本中间函数也是可以从网页HTML中取得需要的内容,那是你没遇到经常改版的网页,并且使用字符串操作来解析网页是非常麻烦的,因为不同的网页字符串标识不一样,而Jsoup不仅使用方便,而且可以像jQuery的选择器那样取数据,非常好用,不吹了,看下面介绍。
Jsoup 是一款 Java 的 HTML 解析器,可直接解析某个 URL 地址、HTML 文本内容。它提供了一套非常省力的 API,可通过 DOM,CSS 以及类似于 jQuery 的操作方法来取出和操作数据。
Jsoup的主要功能:
1. 从一个 URL,文件或字符串中解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找、取出数据;
3. 可操作 HTML 元素、属性、文本;
Jsoup官方地址:https://jsoup.org/download
使用案例
复制
private void getDataByJsoup(){
final NewsInfo newsInfo = new NewsInfo();
final Message message = new Message();
newsList.add(newsInfo);
// 开启一个新线程
new Thread(new Runnable() {
@Override
public void run() {
try {
// 网络加载HTML文档
Document doc = Jsoup.connect("https://voice.hupu.com/nba")
.timeout(5000) // 设置超时时间
.get(); // 使用GET方法访问URL
Elements elements = doc.select("div.list-hd");
for (Element element:elements){
String title = element.select("a").text(); // 新闻标题
String url = element.select("a").attr("href"); // 新闻内容链接
newsInfo.setTitle(title);
newsInfo.setNewsUrl(url);
Log.e("TAG","Jsoup ======>>" + title + url);
}
Elements elements1 = doc.select("div.otherInfo");
for (Element element: elements1){
String time = element.select("a").text(); // 时间
newsInfo.setNewsTime(time);
Log.e("TAG","Jsoup ======>>" + time );
}
message.what = 1;
} catch (IOException e) {
message.what = 2;
e.printStackTrace();
}
handler.sendMessage(message);
}
}).start();
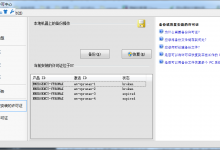
}结果如下图所示:

Android利用Jsoup爬虫框架解析网页html
评论 (0)